As the web continues to change and evolve, our algorithms change right along with it. Recently, as a result of one of those algorithmic changes, we've modified our webmaster guidelines. Previously, these stated:
Don't use "&id=" as a parameter in your URLs, as we don't include these pages in our index.
However, we've recently removed that technical guideline, and now index URLs that contain that parameter. So if your site uses a dynamic structure that generates it, don't worry about rewriting it -- we'll accept it just fine as is. Keep in mind, however, that dynamic URLs with a large number of parameters may be problematic for search engine crawlers in general, so rewriting dynamic URLs into user-friendly versions is always a good practice when that option is available to you. If you can, keeping the number of URL parameters to one or two may make it more likely that search engines will crawl your dynamic urls.
Rabu, 25 Oktober 2006
Kamis, 19 Oktober 2006
Googlebot activity reports
The webmaster tools team has a very exciting mission: we dig into our logs, find as much useful information as possible, and pass it on to you, the webmasters. Our reward is that you more easily understand what Google sees, and why some pages don't make it to the index.
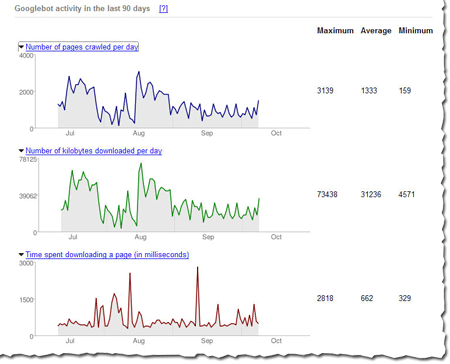
The latest batch of information that we've put together for you is the amount of traffic between Google and a given site. We show you the number of requests, number of kilobytes (yes, yes, I know that tech-savvy webmasters can usually dig this out, but our new charts make it really easy to see at a glance), and the average document download time. You can see this information in chart form, as well as in hard numbers (the maximum, minimum, and average).
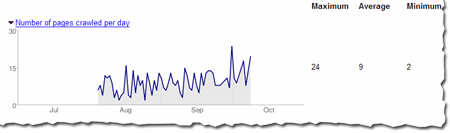
For instance, here's the number of pages Googlebot has crawled in the Webmaster Central blog over the last 90 days. The maximum number of pages Googlebot has crawled in one day is 24 and the minimum is 2. That makes sense, because the blog was launched less than 90 days ago, and the chart shows that the number of pages crawled per day has increased over time. The number of pages crawled is sometimes more than the total number of pages in the site -- especially if the same page can be accessed via several URLs. So http://googlewebmastercentral.blogspot.com/2006/10/learn-more-about-googlebots-crawl-of.html and http://googlewebmastercentral.blogspot.com/2006/10/learn-more-about-googlebots-crawl-of.html#links are different, but point to the same page (the second points to an anchor within the page).

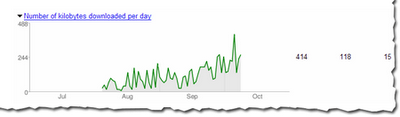
And here's the average number of kilobytes downloaded from this blog each day. As you can see, as the site has grown over the last two and a half months, the number of average kilobytes downloaded has increased as well.
The first two reports can help you diagnose the impact that changes in your site may have on its coverage. If you overhaul your site and dramatically reduce the number of pages, you'll likely notice a drop in the number of pages that Googlebot accesses.
The average document download time can help pinpoint subtle networking problems. If the average time spikes, you might have network slowdowns or bottlenecks that you should investigate. Here's the report for this blog that shows that we did have a short spike in early September (the maximum time was 1057 ms), but it quickly went back to a normal level, so things now look OK.
 In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!
In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!
The latest batch of information that we've put together for you is the amount of traffic between Google and a given site. We show you the number of requests, number of kilobytes (yes, yes, I know that tech-savvy webmasters can usually dig this out, but our new charts make it really easy to see at a glance), and the average document download time. You can see this information in chart form, as well as in hard numbers (the maximum, minimum, and average).
For instance, here's the number of pages Googlebot has crawled in the Webmaster Central blog over the last 90 days. The maximum number of pages Googlebot has crawled in one day is 24 and the minimum is 2. That makes sense, because the blog was launched less than 90 days ago, and the chart shows that the number of pages crawled per day has increased over time. The number of pages crawled is sometimes more than the total number of pages in the site -- especially if the same page can be accessed via several URLs. So http://googlewebmastercentral.blogspot.com/2006/10/learn-more-about-googlebots-crawl-of.html and http://googlewebmastercentral.blogspot.com/2006/10/learn-more-about-googlebots-crawl-of.html#links are different, but point to the same page (the second points to an anchor within the page).
And here's the average number of kilobytes downloaded from this blog each day. As you can see, as the site has grown over the last two and a half months, the number of average kilobytes downloaded has increased as well.

The first two reports can help you diagnose the impact that changes in your site may have on its coverage. If you overhaul your site and dramatically reduce the number of pages, you'll likely notice a drop in the number of pages that Googlebot accesses.
The average document download time can help pinpoint subtle networking problems. If the average time spikes, you might have network slowdowns or bottlenecks that you should investigate. Here's the report for this blog that shows that we did have a short spike in early September (the maximum time was 1057 ms), but it quickly went back to a normal level, so things now look OK.
 In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!
In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!
Selasa, 17 Oktober 2006
Learn more about Googlebot's crawl of your site and more!
We've added a few new features to webmaster tools and invite you to check them out.
If you request a changed crawl rate, this change will last for 90 days. If you liked the changed rate, you can simply return to webmaster tools and make the change again.
Enhanced image search
You can now opt into enhanced image search for the images on your site, which enables our tools such as Google Image Labeler to associate the images included in your site with labels that will improve indexing and search quality of those images. After you've opted in, you can opt out at any time.
 Number of URLs submitted
Number of URLs submitted
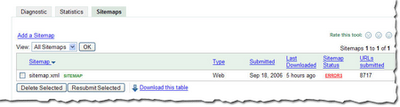
Recently at SES San Jose, a webmaster asked me if we could show the number of URLs we find in a Sitemap. He said that he generates his Sitemaps automatically and he'd like confirmation that the number he thinks he generated is the same number we received. We thought this was a great idea. Simply access the Sitemaps tab to see the number of URLs we found in each Sitemap you've submitted.
 As always, we hope you find these updates useful and look forward to hearing what you think.
As always, we hope you find these updates useful and look forward to hearing what you think.
Googlebot activity reports
Check out these cool charts! We show you the number of pages Googlebot's crawled from your site per day, the number of kilobytes of data Googlebot's downloaded per day, and the average time it took Googlebot to download pages. Webmaster tools show each of these for the last 90 days. Stay tuned for more information about this data and how you can use it to pinpoint issues with your site.
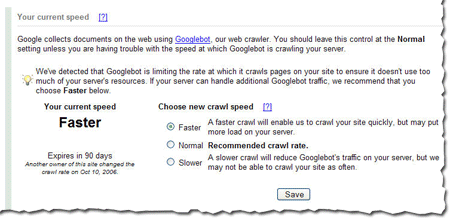
Crawl rate control
Googlebot uses sophisticated algorithms that determine how much to crawl each site. Our goal is to crawl as many pages from your site as we can on each visit without overwhelming your server's bandwidth.
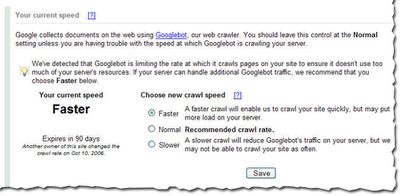
We've been conducting a limited test of a new feature that enables you to provide us information about how we crawl your site. Today, we're making this tool available to everyone. You can access this tool from the Diagnostic tab. If you'd like Googlebot to slow down the crawl of your site, simply choose the Slower option.
If we feel your server could handle the additional bandwidth, and we can crawl your site more, we'll let you know and offer the option for a faster crawl.If you request a changed crawl rate, this change will last for 90 days. If you liked the changed rate, you can simply return to webmaster tools and make the change again.
Enhanced image search
You can now opt into enhanced image search for the images on your site, which enables our tools such as Google Image Labeler to associate the images included in your site with labels that will improve indexing and search quality of those images. After you've opted in, you can opt out at any time.
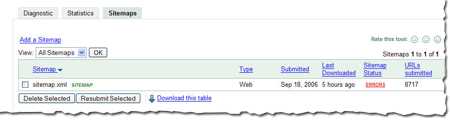
 Number of URLs submitted
Number of URLs submittedRecently at SES San Jose, a webmaster asked me if we could show the number of URLs we find in a Sitemap. He said that he generates his Sitemaps automatically and he'd like confirmation that the number he thinks he generated is the same number we received. We thought this was a great idea. Simply access the Sitemaps tab to see the number of URLs we found in each Sitemap you've submitted.
 As always, we hope you find these updates useful and look forward to hearing what you think.
As always, we hope you find these updates useful and look forward to hearing what you think.
Rabu, 11 Oktober 2006
Got a website? Get gadgets.
 Google Gadgets are miniature-sized devices that offer cool and dynamic content -- they can be games, news clips, weather reports, maps, or most anything you can dream up. They've been around for a while, but their reach got a lot broader last week when we made it possible for anyone to add gadgets to their own webpages. Here's an example of a flight status tracker, for instance, that can be placed on any page on the web for free.
Google Gadgets are miniature-sized devices that offer cool and dynamic content -- they can be games, news clips, weather reports, maps, or most anything you can dream up. They've been around for a while, but their reach got a lot broader last week when we made it possible for anyone to add gadgets to their own webpages. Here's an example of a flight status tracker, for instance, that can be placed on any page on the web for free.Anyone can search for gadgets to add to their own webpage for free in our directory of gadgets for your webpage. To put a gadget on your page, just pick the gadget you like, set your preferences, and copy-and-paste the HTML that is generated for you onto your own page.
Creating gadgets for others isn't hard, either, and it can be a great way to get your content in front of people while they're visiting Google or other sites. Here are a few suggestions for distributing your own content on the Google homepage or other pages across the web:
* Create a Google Gadget for distribution across the web. Gadgets can be most anything, from simple HTML to complex applications. It’s easy to experiment with gadgets – anyone with even a little bit of web design experience can make a simple one (even me!), and more advanced programmers can create really snazzy, complex ones. But remember, it’s also quick and easy for people to delete gadgets or add new ones too their own pages. To help you make sure your gadget will be popular across the web, we provide a few guidelines you can use to create gadgets. The more often folks find your content to be useful, the longer they'll keep your gadget on their pages, and the more often they’ll visit your site.
* If your website has a feed, visitors can put snippets of your content on their own Google homepages quickly and easily, and you don't even need to develop a gadget. However, you will be able to customize their experience much more fully with a gadget than with a feed.
* By putting the “Add to Google” button in a prominent spot on your site, you can increase the reach of your content, because visitors who click to add your gadget or feed to Google can see your content each time they visit the Google homepage. Promoting your own gadget or feed can also increase its popularity, which contributes to a higher ranking in the directory of gadgets for the Google personalized homepage.
Senin, 09 Oktober 2006
Multiple Sitemaps in the same directory
We've gotten a few questions about whether you can put multiple Sitemaps in the same directory. Yes, you can!
You might want to have multiple Sitemap files in a single directory for a number of reasons. For instance, if you have an auction site, you might want to have a daily Sitemap with new auction offers and a weekly Sitemap with less time-sensitive URLs. Or you could generate a new Sitemap every day with new offers, so that the list of Sitemaps grows over time. Either of these solutions works just fine.
Or, here's another sample scenario: Suppose you're a provider that supports multiple web shops, and they share a similar URL structure differentiated by a parameter. For example:
http://example.com/stores/home?id=1
http://example.com/stores/home?id=2
http://example.com/stores/home?id=3
Since they're all in the same directory, it's fine by our rules to put the URLs for all of the stores into a single Sitemap, under http://example.com/ or http://example.com/stores/. However, some webmasters may prefer to have separate Sitemaps for each store, such as:
http://example.com/stores/store1_sitemap.xml
http://example.com/stores/store2_sitemap.xml
http://example.com/stores/store3_sitemap.xml
As long as all URLs listed in the Sitemap are at the same location as the Sitemap or in a sub directory (in the above example http://example.com/stores/ or perhaps http://example.com/stores/catalog) it's fine for multiple Sitemaps to live in the same directory (as many as you want!). The important thing is that Sitemaps not contain URLs from parent directories or completely different directories -- if that happens, we can't be sure that the submitter controls the URL's directory, so we can't trust the metadata.
The above Sitemaps could also be collected into a single Sitemap index file and easily be submitted via Google webmaster tools. For example, you could create http://example.com/stores/sitemap_index.xml as follows:
Then simply add the index file to your account, and you'll be able to see any errors for each of the child Sitemaps.
If each store includes more than 50,000 URLs (the maximum number for a single Sitemap), you would need to have multiple Sitemaps for each store. In that case, you may want to create a Sitemap index file for each store that lists the Sitemaps for that store. For instance:
http://example.com/stores/store1_sitemapindex.xml
http://example.com/stores/store2_sitemapindex.xml
http://example.com/stores/store3_sitemapindex.xml
Since Sitemap index files can't contain other index files, you would need to submit each Sitemap index file to your account separately.
Whether you list all URLs in a single Sitemap or in multiple Sitemaps (in the same directory of different directories) is simply based on what's easiest for you to maintain. We treat the URLs equally for each of these methods of organization.
You might want to have multiple Sitemap files in a single directory for a number of reasons. For instance, if you have an auction site, you might want to have a daily Sitemap with new auction offers and a weekly Sitemap with less time-sensitive URLs. Or you could generate a new Sitemap every day with new offers, so that the list of Sitemaps grows over time. Either of these solutions works just fine.
Or, here's another sample scenario: Suppose you're a provider that supports multiple web shops, and they share a similar URL structure differentiated by a parameter. For example:
http://example.com/stores/home?id=1
http://example.com/stores/home?id=2
http://example.com/stores/home?id=3
Since they're all in the same directory, it's fine by our rules to put the URLs for all of the stores into a single Sitemap, under http://example.com/ or http://example.com/stores/. However, some webmasters may prefer to have separate Sitemaps for each store, such as:
http://example.com/stores/store1_sitemap.xml
http://example.com/stores/store2_sitemap.xml
http://example.com/stores/store3_sitemap.xml
As long as all URLs listed in the Sitemap are at the same location as the Sitemap or in a sub directory (in the above example http://example.com/stores/ or perhaps http://example.com/stores/catalog) it's fine for multiple Sitemaps to live in the same directory (as many as you want!). The important thing is that Sitemaps not contain URLs from parent directories or completely different directories -- if that happens, we can't be sure that the submitter controls the URL's directory, so we can't trust the metadata.
The above Sitemaps could also be collected into a single Sitemap index file and easily be submitted via Google webmaster tools. For example, you could create http://example.com/stores/sitemap_index.xml as follows:
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.google.com/schemas/sitemap/0.84">
<sitemap>
<loc>http://example.com/stores/store1_sitemap.xml</loc>
<lastmod>2006-10-01T18:23:17+00:00</lastmod>
</sitemap>
<sitemap>
<loc>http://example.com/stores/store2_sitemap.xml</loc>
<lastmod>2006-10-01</lastmod>
</sitemap>
<sitemap>
<loc>http://example.com/stores/store3_sitemap.xml</loc>
<lastmod>2006-10-05</lastmod>
</sitemap>
</sitemapindex>
Then simply add the index file to your account, and you'll be able to see any errors for each of the child Sitemaps.
If each store includes more than 50,000 URLs (the maximum number for a single Sitemap), you would need to have multiple Sitemaps for each store. In that case, you may want to create a Sitemap index file for each store that lists the Sitemaps for that store. For instance:
http://example.com/stores/store1_sitemapindex.xml
http://example.com/stores/store2_sitemapindex.xml
http://example.com/stores/store3_sitemapindex.xml
Since Sitemap index files can't contain other index files, you would need to submit each Sitemap index file to your account separately.
Whether you list all URLs in a single Sitemap or in multiple Sitemaps (in the same directory of different directories) is simply based on what's easiest for you to maintain. We treat the URLs equally for each of these methods of organization.
Kamis, 05 Oktober 2006
Useful information you may have missed
When we launched this blog in early August, we said goodbye to the Inside Google Sitemaps blog and started redirecting it here. The redirect makes the posts we did there a little difficult to get to. For those of you who started reading with this newer blog, here are links to some of the older posts that may be of interest.
Webmaster Tools Account questions
- Tips from BlogHer | More tips
- Opting-out of Open Directory Project descriptions and titles in our search results
- Tips for non-US sites
- Information on robots.txt files | More tips on using a robots.txt file
- Improving your site's indexing and ranking 101
- Changing domain names | More about changing domain names
Webmaster Tools Account questions
- Can multiple account holders view information for a site?
- About meta tag verification
- About the common words feature
- Changing your Sitemap when your site changes
- Do you have to include every page from your site in your Sitemap?
- If you try to verify and get the error: We've detected that your 404 (file not found) error page returns a status of 200 (OK) in the header
- Submitting mobile Sitemaps
Kamis, 28 September 2006
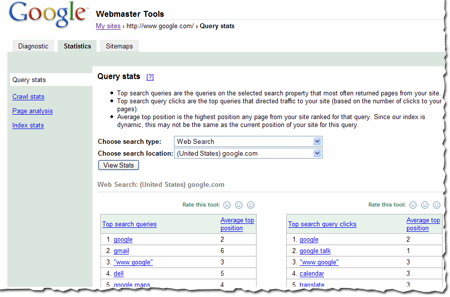
Fresher query stats
Query stats in webmaster tools provide information about the search queries that most often return your site in the results. You can view this information by a variety of search types (such as web search, mobile search, or image search) and countries. We show you the top search types and locations for your site. You can access these stats by selecting a verified site in your account and then choosing Query stats from the Statistics tab.
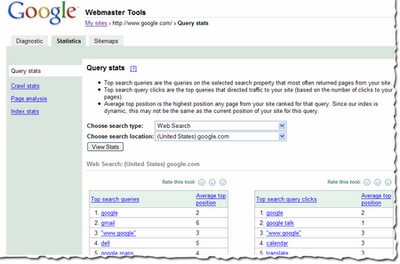
If you've checked your site's query stats lately, you may have noticed that they're changing more often than they used to. This is because we recently changed how frequently we calculate them. Previously, we showed data that was averaged over a period of three weeks. Now, we show data that is averaged over a period of one week. This results in fresher stats for you, as well as stats that more accurately reflect the current queries that return your site in the results. We update these stats every week, so if you'd like to keep a history of the top queries for your site week by week, you can simply download the data each week. We generally update this data each Monday.
How we calculate query stats
Some of you have asked how we calculate query stats.
These results are based on results that searchers see. For instance, say a search for [Britney Spears] brings up your site as position 21, which is on the third page of the results. And say 1000 people searched for [Britney Spears] during the course of a week (in reality, a few more people than that search for her name, but just go with me for this example). 600 of those people only looked at the first page of results and the other 400 browsed to at least the third page. That means that your site was seen by 400 searchers. Even though your site was at position 21 for all 1000 searchers, only 400 are counted for purposes of this calculation.
Both top search queries and top search query clicks are based on the total number of searches for each query. The stats we show are based on the queries that most often return your site in the results. For instance, going back to that familiar [Britney Spears] query -- 400 searchers saw your site in the results. Now, maybe your site isn't really about Britney Spears -- it's more about Buffy the Vampire Slayer. And say Google received 50 queries for [Buffy the Vampire Slayer] in the same week, and your site was returned in the results at position 2. So, all 50 searchers saw your site in the results. In this example, Britney Spears would show as a top search query above Buffy the Vampire Slayer (because your site was seen by 400 searchers for Britney but 50 searchers for Buffy).
The same is true of top search query clicks. If 100 of the Britney-seekers clicked on your site in the search results and all 50 of the Buffy-searchers click on your site in the search results, Britney would show as a top search query above Buffy.
At times, this may cause some of the query stats we show you to seem unusual. If your site is returned for a very high-traffic query, then even if a low percentage of searchers click on your site for that query, the total number of searchers who click on your site may still be higher for the query than for queries for which a much higher percentage of searchers click on your site in the results.
The average top position for top search queries is the position of the page on your site that ranks most highly for the query. The average top position for top search query clicks is the position of the page on your site that searchers clicked on (even if a different page ranked more highly for the query). We show you the average position for this top page across all data centers over the course of the week.
A variety of download options are available. You can:
If you've checked your site's query stats lately, you may have noticed that they're changing more often than they used to. This is because we recently changed how frequently we calculate them. Previously, we showed data that was averaged over a period of three weeks. Now, we show data that is averaged over a period of one week. This results in fresher stats for you, as well as stats that more accurately reflect the current queries that return your site in the results. We update these stats every week, so if you'd like to keep a history of the top queries for your site week by week, you can simply download the data each week. We generally update this data each Monday.
How we calculate query stats
Some of you have asked how we calculate query stats.
These results are based on results that searchers see. For instance, say a search for [Britney Spears] brings up your site as position 21, which is on the third page of the results. And say 1000 people searched for [Britney Spears] during the course of a week (in reality, a few more people than that search for her name, but just go with me for this example). 600 of those people only looked at the first page of results and the other 400 browsed to at least the third page. That means that your site was seen by 400 searchers. Even though your site was at position 21 for all 1000 searchers, only 400 are counted for purposes of this calculation.
Both top search queries and top search query clicks are based on the total number of searches for each query. The stats we show are based on the queries that most often return your site in the results. For instance, going back to that familiar [Britney Spears] query -- 400 searchers saw your site in the results. Now, maybe your site isn't really about Britney Spears -- it's more about Buffy the Vampire Slayer. And say Google received 50 queries for [Buffy the Vampire Slayer] in the same week, and your site was returned in the results at position 2. So, all 50 searchers saw your site in the results. In this example, Britney Spears would show as a top search query above Buffy the Vampire Slayer (because your site was seen by 400 searchers for Britney but 50 searchers for Buffy).
The same is true of top search query clicks. If 100 of the Britney-seekers clicked on your site in the search results and all 50 of the Buffy-searchers click on your site in the search results, Britney would show as a top search query above Buffy.
At times, this may cause some of the query stats we show you to seem unusual. If your site is returned for a very high-traffic query, then even if a low percentage of searchers click on your site for that query, the total number of searchers who click on your site may still be higher for the query than for queries for which a much higher percentage of searchers click on your site in the results.
The average top position for top search queries is the position of the page on your site that ranks most highly for the query. The average top position for top search query clicks is the position of the page on your site that searchers clicked on (even if a different page ranked more highly for the query). We show you the average position for this top page across all data centers over the course of the week.
A variety of download options are available. You can:
- download individual tables of data by clicking the Download this table link.
- download stats for all subfolders on your site (for all search types and locations) by clicking the Download all query stats for this site (including subfolders) link.
- download all stats (including query stats) for all verified sites in your account by choosing Tools from the My Sites page, then choosing Download data for all sites and then Download statistics for all sites.
Rabu, 27 September 2006
Introducing Google Checkout
For you webmasters that manage sites that sell online, we'd like to introduce you to one of our newest products, Google Checkout. Google Checkout is a checkout process that you integrate with your site(s), enabling your customers to quickly buy from you by providing only a single username and password. From there, you can use Checkout to charge your customers' credit cards and process their orders.
Users of Google's search advertising program, AdWords, get the added benefit of the Google Checkout badge and free transaction processing. The Google Checkout badge is an icon that appears on your AdWords ads and improves the effectiveness of your advertising by letting searchers know that you accept Checkout. Also, for every $1 you spend on AdWords, you can process $10 of Checkout sales for free. Even if you don't use AdWords, you can still process sales for a low 2% and $0.20 per transaction. So if you're interested in implementing Google Checkout, we encourage you to learn more.
If you're managing the sites of other sellers, you might want to sign up for our merchant referral program where you can earn cash for helping your sellers get up and running with Google Checkout. You can earn $25 for every merchant you refer that processes at least 3 unique customer transactions and $500 in Checkout sales. And you can earn $5 for every $1,000 of Checkout sales processed by the merchants you refer. If you're interested, apply here.
Users of Google's search advertising program, AdWords, get the added benefit of the Google Checkout badge and free transaction processing. The Google Checkout badge is an icon that appears on your AdWords ads and improves the effectiveness of your advertising by letting searchers know that you accept Checkout. Also, for every $1 you spend on AdWords, you can process $10 of Checkout sales for free. Even if you don't use AdWords, you can still process sales for a low 2% and $0.20 per transaction. So if you're interested in implementing Google Checkout, we encourage you to learn more.
If you're managing the sites of other sellers, you might want to sign up for our merchant referral program where you can earn cash for helping your sellers get up and running with Google Checkout. You can earn $25 for every merchant you refer that processes at least 3 unique customer transactions and $500 in Checkout sales. And you can earn $5 for every $1,000 of Checkout sales processed by the merchants you refer. If you're interested, apply here.
Rabu, 20 September 2006
How to verify Googlebot
Lately I've heard a couple smart people ask that search engines provide a way know that a bot is authentic. After all, any spammer could name their bot "Googlebot" and claim to be Google, so which bots do you trust and which do you block?
The common request we hear is to post a list of Googlebot IP addresses in some public place. The problem with that is that if/when the IP ranges of our crawlers change, not everyone will know to check. In fact, the crawl team migrated Googlebot IPs a couple years ago and it was a real hassle alerting webmasters who had hard-coded an IP range. So the crawl folks have provided another way to authenticate Googlebot. Here's an answer from one of the crawl people (quoted with their permission):
This answer has also been provided to our help-desk, so I'd consider it an official way to authenticate Googlebot. In order to fetch from the "official" Googlebot IP range, the bot has to respect robots.txt and our internal hostload conventions so that Google doesn't crawl you too hard.
(Thanks to N. and J. for help on this answer from the crawl side of things.)
The common request we hear is to post a list of Googlebot IP addresses in some public place. The problem with that is that if/when the IP ranges of our crawlers change, not everyone will know to check. In fact, the crawl team migrated Googlebot IPs a couple years ago and it was a real hassle alerting webmasters who had hard-coded an IP range. So the crawl folks have provided another way to authenticate Googlebot. Here's an answer from one of the crawl people (quoted with their permission):
Telling webmasters to use DNS to verify on a case-by-case basis seems like the best way to go. I think the recommended technique would be to do a reverse DNS lookup, verify that the name is in the googlebot.com domain, and then do a corresponding forward DNS->IP lookup using that googlebot.com name; eg:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
I don't think just doing a reverse DNS lookup is sufficient, because a spoofer could set up reverse DNS to point to crawl-a-b-c-d.googlebot.com.
This answer has also been provided to our help-desk, so I'd consider it an official way to authenticate Googlebot. In order to fetch from the "official" Googlebot IP range, the bot has to respect robots.txt and our internal hostload conventions so that Google doesn't crawl you too hard.
(Thanks to N. and J. for help on this answer from the crawl side of things.)
Selasa, 19 September 2006
Debugging blocked URLs
Vanessa's been posting a lot lately, and I'm starting to feel left out. So here my tidbit of wisdom for you: I've noticed a couple of webmasters confused by "blocked by robots.txt" errors, and I wanted to share the steps I take when debugging robots.txt problems:
A handy checklist for debugging a blocked URL
Ask for help
Finally, if you still can't pinpoint the problem, you might want to post on our forum for help. Be sure to include the URL that is blocked in your message. Sometimes its easier for other people to notice oversights you may have missed.
Good luck debugging! And by the way -- unrelated to robots.txt -- make sure that you don't have "noindex" meta tags at the top of your web pages; those also result in Google not showing a web site in our index.
A handy checklist for debugging a blocked URL
Let's assume you are looking at crawl errors for your website and notice a URL restricted by robots.txt that you weren't intending to block:
http://www.example.com/amanda.html URL restricted by robots.txt Sep 3, 2006
Check the robots.txt analysis tool
The first thing you should do is go to the robots.txt analysis tool for that site. Make sure you are looking at the correct site for that URL, paying attention that you are looking at the right protocol and subdomain. (Subdomains and protocols may have their own robots.txt file, so https://www.example.com/robots.txt may be different from http://example.com/robots.txt and may be different from http://amanda.example.com/robots.txt.) Paste the blocked URL into the "Test URLs against this robots.txt file" box. If the tool reports that it is blocked, you've found your problem. If the tool reports that it's allowed, we need to investigate further.
At the top of the robots.txt analysis tool, take a look at the HTTP status code. If we are reporting anything other than a 200 (Success) or a 404 (Not found) then we may not be able to reach your robots.txt file, which stops our crawling process. (Note that you can see the last time we downloaded your robots.txt file at the top of this tool. If you make changes to your file, check this date and time to see if your changes were made after our last download.)
Check for changes in your robots.txt file
If these look fine, you may want to check and see if your robots.txt file has changed since the error occurred by checking the date to see when your robots.txt file was last modified. If it was modified after the date given for the error in the crawl errors, it might be that someone has changed the file so that the new version no longer blocks this URL.
Check for redirects of the URL
If you can be certain that this URL isn't blocked, check to see if the URL redirects to another page. When Googlebot fetches a URL, it checks the robots.txt file to make sure it is allowed to access the URL. If the robots.txt file allows access to the URL, but the URL returns a redirect, Googlebot checks the robots.txt file again to see if the destination URL is accessible. If at any point Googlebot is redirected to a blocked URL, it reports that it could not get the content of the original URL because it was blocked by robots.txt.
Sometimes this behavior is easy to spot because a particular URL always redirects to another one. But sometimes this can be tricky to figure out. For instance:
http://www.example.com/amanda.html URL restricted by robots.txt Sep 3, 2006
Check the robots.txt analysis tool
The first thing you should do is go to the robots.txt analysis tool for that site. Make sure you are looking at the correct site for that URL, paying attention that you are looking at the right protocol and subdomain. (Subdomains and protocols may have their own robots.txt file, so https://www.example.com/robots.txt may be different from http://example.com/robots.txt and may be different from http://amanda.example.com/robots.txt.) Paste the blocked URL into the "Test URLs against this robots.txt file" box. If the tool reports that it is blocked, you've found your problem. If the tool reports that it's allowed, we need to investigate further.
At the top of the robots.txt analysis tool, take a look at the HTTP status code. If we are reporting anything other than a 200 (Success) or a 404 (Not found) then we may not be able to reach your robots.txt file, which stops our crawling process. (Note that you can see the last time we downloaded your robots.txt file at the top of this tool. If you make changes to your file, check this date and time to see if your changes were made after our last download.)
Check for changes in your robots.txt file
If these look fine, you may want to check and see if your robots.txt file has changed since the error occurred by checking the date to see when your robots.txt file was last modified. If it was modified after the date given for the error in the crawl errors, it might be that someone has changed the file so that the new version no longer blocks this URL.
Check for redirects of the URL
If you can be certain that this URL isn't blocked, check to see if the URL redirects to another page. When Googlebot fetches a URL, it checks the robots.txt file to make sure it is allowed to access the URL. If the robots.txt file allows access to the URL, but the URL returns a redirect, Googlebot checks the robots.txt file again to see if the destination URL is accessible. If at any point Googlebot is redirected to a blocked URL, it reports that it could not get the content of the original URL because it was blocked by robots.txt.
Sometimes this behavior is easy to spot because a particular URL always redirects to another one. But sometimes this can be tricky to figure out. For instance:
- Your site may not have a robots.txt file at all (and therefore, allows access to all pages), but a URL on the site may redirect to a different site, which does have a robots.txt file. In this case, you may see URLs blocked by robots.txt for your site (even though you don't have a robots.txt file).
- Your site may prompt for registration after a certain number of page views. You may have the registration page blocked by a robots.txt file. In this case, the URL itself may not redirect, but if Googlebot triggers the registration prompt when accessing the URL, it will be redirected to the blocked registration page, and the original URL will be listed in the crawl errors page as blocked by robots.txt.
Ask for help
Finally, if you still can't pinpoint the problem, you might want to post on our forum for help. Be sure to include the URL that is blocked in your message. Sometimes its easier for other people to notice oversights you may have missed.
Good luck debugging! And by the way -- unrelated to robots.txt -- make sure that you don't have "noindex" meta tags at the top of your web pages; those also result in Google not showing a web site in our index.
Jumat, 15 September 2006
For Those Wondering About Public Service Search
Update: The described product or service is no longer available. More information.
We recently learned of a security issue with our Public Service Search service and disabled login functionality temporarily to protect our Public Service Search users while we were working to fix the problem. We are not aware of any malicious exploits of this problem and this service represents an extremely small portion of searches.
We have a temporary fix in place currently that prevents exploitation of this problem and will have a permanent solution in place shortly. Unfortunately, the temporary fix may inconvenience a small number of Public Service Search users in the following ways:
* Public Service Search is currently not open to new signups.
* If you use Public Service Search on your site, you are currently unable to log in to make changes, but rest assured that Public Service Search continues to function properly on your site.
* The template system is currently disabled, so search results will appear in a standard Google search results format, rather than customized to match the look and feel of your site. However, the search results themselves are not being modified.
If you are a Public Service Search user and are having trouble logging in right now, please sit tight. As soon as the permanent solution is in place the service will be back on its feet again. In the meantime, you will still be able to provide site-specific searches on your site as usual.
Google introduced this service several years ago to support universities and non-profit organizations by offering ad-free search capabilities for their sites. Our non-profit and university users are extremely important to us and we apologize for any inconvenience this may cause.
Please post any questions or concerns in our webmaster discussion forum and we'll try our best to answer any questions you may have.
We have a temporary fix in place currently that prevents exploitation of this problem and will have a permanent solution in place shortly. Unfortunately, the temporary fix may inconvenience a small number of Public Service Search users in the following ways:
* Public Service Search is currently not open to new signups.
* If you use Public Service Search on your site, you are currently unable to log in to make changes, but rest assured that Public Service Search continues to function properly on your site.
* The template system is currently disabled, so search results will appear in a standard Google search results format, rather than customized to match the look and feel of your site. However, the search results themselves are not being modified.
If you are a Public Service Search user and are having trouble logging in right now, please sit tight. As soon as the permanent solution is in place the service will be back on its feet again. In the meantime, you will still be able to provide site-specific searches on your site as usual.
Google introduced this service several years ago to support universities and non-profit organizations by offering ad-free search capabilities for their sites. Our non-profit and university users are extremely important to us and we apologize for any inconvenience this may cause.
Please post any questions or concerns in our webmaster discussion forum and we'll try our best to answer any questions you may have.
Selasa, 12 September 2006
Setting the preferred domain
Based on your input, we've recently made a few changes to the preferred domain feature of webmaster tools. And since you've had some questions about this feature, we'd like to answer them.
The preferred domain feature enables you to tell us if you'd like URLs from your site crawled and indexed using the www version of the domain (http://www.example.com) or the non-www version of the domain (http://example.com). When we initially launched this, we added the non-preferred version to your account when you specified a preference so that you could see any information associated with the non-preferred version. But many of you found that confusing, so we've made the following changes:
Here are some questions we've had about this preferred domain feature, and our replies.
Once I've set my preferred domain, how long will it take before I see changes?
The time frame depends on many factors (such as how often your site is crawled and how many pages are indexed with the non-preferred version). You should start to see changes in the few weeks after you set your preferred domain.
Is the preferred domain feature a filter or a redirect? Does it simply cause the search results to display on the URLs that are in the version I prefer?
The preferred domain feature is not a filter. When you set a preference, we:
You don't have to use it, as we can follow the redirects. However, you still can benefit from using this feature in two ways: we can more easily consolidate links to your site and over time, we'll direct our crawl to the preferred version of your pages.
If I use this feature, should I still use a 301 redirect on my site?
You don't need to use it for Googlebot, but you should still use the 301 redirect, if it's available. This will help visitors and other search engines. Of course, make sure that you point to the same URL with the preferred domain feature and the 301 redirect.
You can find more about this in our webmaster help center.
The preferred domain feature enables you to tell us if you'd like URLs from your site crawled and indexed using the www version of the domain (http://www.example.com) or the non-www version of the domain (http://example.com). When we initially launched this, we added the non-preferred version to your account when you specified a preference so that you could see any information associated with the non-preferred version. But many of you found that confusing, so we've made the following changes:
- When you set the preferred domain, we no longer will add the non-preferred version to your account.
- If you had previously added the non-preferred version to your account, you'll still see it listed there, but you won't be able to add a Sitemap for the non-preferred version.
- If you have already set the preferred domain and we had added the non-preferred version to your account, we'll be removing that non-preferred version from your account over the next few days.
Here are some questions we've had about this preferred domain feature, and our replies.
Once I've set my preferred domain, how long will it take before I see changes?
The time frame depends on many factors (such as how often your site is crawled and how many pages are indexed with the non-preferred version). You should start to see changes in the few weeks after you set your preferred domain.
Is the preferred domain feature a filter or a redirect? Does it simply cause the search results to display on the URLs that are in the version I prefer?
The preferred domain feature is not a filter. When you set a preference, we:
- Consider all links that point to the site (whether those links use the www version or the non-www version) to be pointing at the version you prefer. This helps us more accurately determine PageRank for your pages.
- Once we know that both versions of a URL point to the same page, we try to select the preferred version for future crawls.
- Index pages of your site using the version you prefer. If some pages of your site are indexed using the www version and other pages are indexed using the non-www version, then over time, you should see a shift to the preference you've set.
You don't have to use it, as we can follow the redirects. However, you still can benefit from using this feature in two ways: we can more easily consolidate links to your site and over time, we'll direct our crawl to the preferred version of your pages.
If I use this feature, should I still use a 301 redirect on my site?
You don't need to use it for Googlebot, but you should still use the 301 redirect, if it's available. This will help visitors and other search engines. Of course, make sure that you point to the same URL with the preferred domain feature and the 301 redirect.
You can find more about this in our webmaster help center.
Kamis, 07 September 2006
Information about Sitelinks
You may have noticed that some search results include a set of links below them to pages within the site. We've just updated our help center with information on how we generate these links, called Sitelinks, and why we show them.
Our process for generating Sitelinks is completely automated. We show them when we think they'll be most useful to searchers, saving them time from hunting through web pages to find the information they are looking for. Over time, we may look for ways to incorporate input from webmasters too.
Our process for generating Sitelinks is completely automated. We show them when we think they'll be most useful to searchers, saving them time from hunting through web pages to find the information they are looking for. Over time, we may look for ways to incorporate input from webmasters too.
Selasa, 05 September 2006
Better details about when Googlebot last visited a page
Most people know that Googlebot downloads pages from web servers to crawl the web. Not as many people know that if Googlebot accesses a page and gets a 304 (Not-Modified) response to a If-Modified-Since qualified request, Googlebot doesn't download the contents of that page. This reduces the bandwidth consumed on your web server.
When you look at Google's cache of a page (for instance, by using the cache: operator or clicking the Cached link under a URL in the search results), you can see the date that Googlebot retrieved that page. Previously, the date we listed for the page's cache was the date that we last successfully fetched the content of the page. This meant that even if we visited a page very recently, the cache date might be quite a bit older if the page hadn't changed since the previous visit. This made it difficult for webmasters to use the cache date we display to determine Googlebot's most recent visit. Consider the following example:
Note that this change will be reflected for individual pages as we update those pages in our index.
When you look at Google's cache of a page (for instance, by using the cache: operator or clicking the Cached link under a URL in the search results), you can see the date that Googlebot retrieved that page. Previously, the date we listed for the page's cache was the date that we last successfully fetched the content of the page. This meant that even if we visited a page very recently, the cache date might be quite a bit older if the page hadn't changed since the previous visit. This made it difficult for webmasters to use the cache date we display to determine Googlebot's most recent visit. Consider the following example:
- Googlebot crawls a page on April 12, 2006.
- Our cached version of that page notes that "This is G o o g l e's cache of http://www.example.com/ as retrieved on April 12, 2006 20:02:06 GMT."
- Periodically, Googlebot checks to see if that page has changed, and each time, receives a Not-Modified response. For instance, on August 27, 2006, Googlebot checks the page, receives a Not-Modified response, and therefore, doesn't download the contents of the page.
- On August 28, 2006, our cached version of the page still shows the April 12, 2006 date -- the date we last downloaded the page's contents, even though Googlebot last visited the day before.
Note that this change will be reflected for individual pages as we update those pages in our index.
Kamis, 31 Agustus 2006
How search results may differ based on accented characters and interface languages
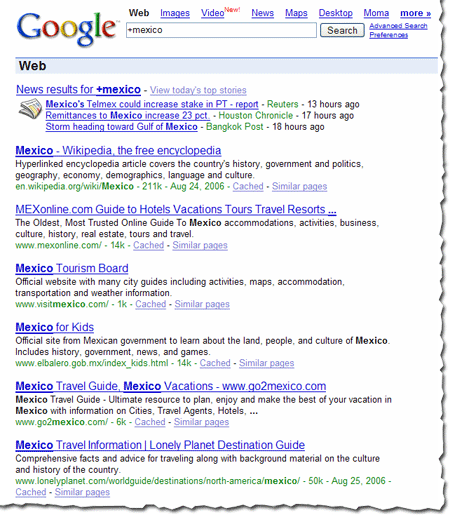
When a searcher enters a query that includes a word with accented characters, our algorithms consider web pages that contain versions of that word both with and without the accent. For instance, if a searcher enters [México], we'll return results for pages about both "Mexico" and "México."
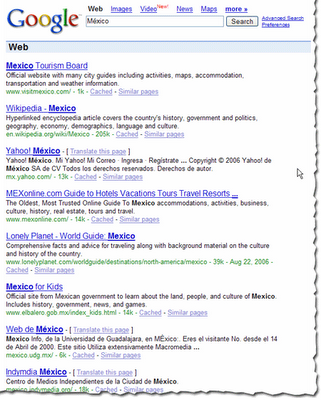
Conversely, if a searcher enters a query without using accented characters, but a word in that query could be spelled with them, our algorithms consider web pages with both the accented and non-accented versions of the word. So if a searcher enters [Mexico], we'll return results for pages about both "Mexico" and "México."

How the searcher's interface language comes into play
The searcher's interface language is taken into account during this process. For instance, the set of accented characters that are treated as equivalent to non-accented characters varies based on the searcher's interface language, as language-level rules for accenting differ.
Also, documents in the chosen interface language tend to be considered more relevant. If a searcher's interface language is English, our algorithms assume that the queries are in English and that the searcher prefers English language documents returned.
This means that the search results for the same query can vary depending on the language interface of the searcher. They can also vary depending on the location of the searcher (which is based on IP address) and if the searcher chooses to see results only from the specified language. If the searcher has personalized search enabled, that will also influence the search results.
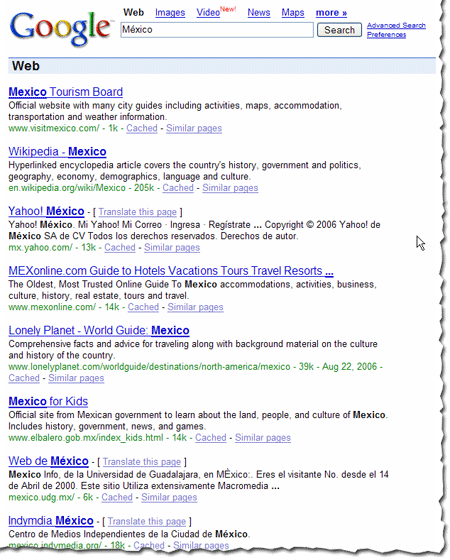
The example below illustrates the results returned when a searcher queries [Mexico] with the interface language set to Spanish.

Note that when the interface language is set to Spanish, more results with accented characters are returned, even though the query didn't include the accented character.
How to restrict search results
To obtain search results for only a specific version of the word (with or without accented characters), you can place a + before the word. For instance, the search [+Mexico] returns only pages about "Mexico" (and not "México"). The search [+México] returns only pages about "México" and not "Mexico." Note that you may see some search results that don't appear to use the version of word you specified in your query, but that version of the word may appear within the content of the page or in anchor text to the page, rather than in the title or description listed in the results. (You can see the top anchor text used to link to your site by choosing Statistics > Page analysis in webmaster tools.)
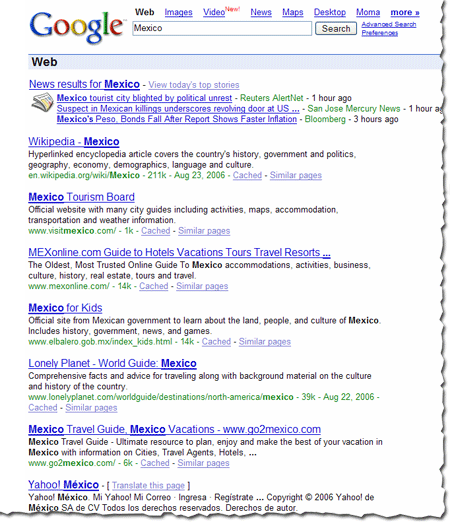
The example below illustrates the results returned when a searcher queries [+Mexico].

Conversely, if a searcher enters a query without using accented characters, but a word in that query could be spelled with them, our algorithms consider web pages with both the accented and non-accented versions of the word. So if a searcher enters [Mexico], we'll return results for pages about both "Mexico" and "México."
How the searcher's interface language comes into play
The searcher's interface language is taken into account during this process. For instance, the set of accented characters that are treated as equivalent to non-accented characters varies based on the searcher's interface language, as language-level rules for accenting differ.
Also, documents in the chosen interface language tend to be considered more relevant. If a searcher's interface language is English, our algorithms assume that the queries are in English and that the searcher prefers English language documents returned.
This means that the search results for the same query can vary depending on the language interface of the searcher. They can also vary depending on the location of the searcher (which is based on IP address) and if the searcher chooses to see results only from the specified language. If the searcher has personalized search enabled, that will also influence the search results.
The example below illustrates the results returned when a searcher queries [Mexico] with the interface language set to Spanish.

Note that when the interface language is set to Spanish, more results with accented characters are returned, even though the query didn't include the accented character.
How to restrict search results
To obtain search results for only a specific version of the word (with or without accented characters), you can place a + before the word. For instance, the search [+Mexico] returns only pages about "Mexico" (and not "México"). The search [+México] returns only pages about "México" and not "Mexico." Note that you may see some search results that don't appear to use the version of word you specified in your query, but that version of the word may appear within the content of the page or in anchor text to the page, rather than in the title or description listed in the results. (You can see the top anchor text used to link to your site by choosing Statistics > Page analysis in webmaster tools.)
The example below illustrates the results returned when a searcher queries [+Mexico].
Rabu, 30 Agustus 2006
Listen in - Matt Cutts and Vanessa Fox talk search
Tune into Webmaster Radio Thursday, August 31 at 1 pm Pacific to hear Matt Cutts and me take over GoodKarma while GoodROI (Greg Niland), the program's regular host, is on vacation. We'll talk about a little of everything, including giving Danny Sullivan career advice (if he ever decides to get out of search -- which we hope he never does -- he can always pursue a career in song), Google's handling of words with accented characters, display date changes in Google cached pages, and the not-so-nice side of SEO.
And if you missed last week's show, check out the podcast. Danny Sullivan and I explained that everything you need to know about search marketing, you can learn by watching Buffy the Vampire Slayer. If you heard the show and are worried about Danny's favorite espresso machine shop, don't be. They're doing OK after all.
And if you missed last week's show, check out the podcast. Danny Sullivan and I explained that everything you need to know about search marketing, you can learn by watching Buffy the Vampire Slayer. If you heard the show and are worried about Danny's favorite espresso machine shop, don't be. They're doing OK after all.
Rabu, 23 Agustus 2006
System maintenance
We're currently doing routine system maintenance, and some data may not be available in your webmaster tools account today. We're working as quickly as possible, and all information should be available again by Thursday, 8/24. Thank you for your patience in the meantime.
Update: We're still finishing some things up, so thanks for bearing with us. Note that the preferred domain feature is currently unavailable, but will available as soon as our maintenance is complete.
Update: We're still finishing some things up, so thanks for bearing with us. Note that the preferred domain feature is currently unavailable, but will available as soon as our maintenance is complete.
Sabtu, 19 Agustus 2006
All About Googlebot
I've seen a lot of questions lately about robots.txt files and Googlebot's behavior. Last week at SES, I spoke on a new panel called the Bot Obedience course. And a few days ago, some other Googlers and I fielded questions on the WebmasterWorld forums. Here are some of the questions we got:
If my site is down for maintenance, how can I tell Googlebot to come back later rather than to index the "down for maintenance" page?
You should configure your server to return a status of 503 (network unavailable) rather than 200 (successful). That lets Googlebot know to try the pages again later.
What should I do if Googlebot is crawling my site too much?
You can contact us -- we'll work with you to make sure we don't overwhelm your server's bandwidth. We're experimenting with a feature in our webmaster tools for you to provide input on your crawl rate, and have gotten great feedback so far, so we hope to offer it to everyone soon.
Is it better to use the meta robots tag or a robots.txt file?
Googlebot obeys either, but meta tags apply to single pages only. If you have a number of pages you want to exclude from crawling, you can structure your site in such a way that you can easily use a robots.txt file to block those pages (for instance, put the pages into a single directory).
If my robots.txt file contains a directive for all bots as well as a specific directive for Googlebot, how does Googlebot interpret the line addressed to all bots?
If your robots.txt file contains a generic or weak directive plus a directive specifically for Googlebot, Googlebot obeys the lines specifically directed at it.
For instance, for this robots.txt file:
For this robots.txt file:
If you're not sure how Googlebot will interpret your robots.txt file, you can use our robots.txt analysis tool to test it. You can also test how Googlebot will interpret changes to the file.
For complete information on how Googlebot and Google's other user agents treat robots.txt files, see our webmaster help center.
If my site is down for maintenance, how can I tell Googlebot to come back later rather than to index the "down for maintenance" page?
You should configure your server to return a status of 503 (network unavailable) rather than 200 (successful). That lets Googlebot know to try the pages again later.
What should I do if Googlebot is crawling my site too much?
You can contact us -- we'll work with you to make sure we don't overwhelm your server's bandwidth. We're experimenting with a feature in our webmaster tools for you to provide input on your crawl rate, and have gotten great feedback so far, so we hope to offer it to everyone soon.
Is it better to use the meta robots tag or a robots.txt file?
Googlebot obeys either, but meta tags apply to single pages only. If you have a number of pages you want to exclude from crawling, you can structure your site in such a way that you can easily use a robots.txt file to block those pages (for instance, put the pages into a single directory).
If my robots.txt file contains a directive for all bots as well as a specific directive for Googlebot, how does Googlebot interpret the line addressed to all bots?
If your robots.txt file contains a generic or weak directive plus a directive specifically for Googlebot, Googlebot obeys the lines specifically directed at it.
For instance, for this robots.txt file:
User-agent: *Googlebot will crawl everything in the site other than pages in the cgi-bin directory.
Disallow: /
User-agent: Googlebot
Disallow: /cgi-bin/
For this robots.txt file:
User-agent: *Googlebot won't crawl any pages of the site.
Disallow: /
If you're not sure how Googlebot will interpret your robots.txt file, you can use our robots.txt analysis tool to test it. You can also test how Googlebot will interpret changes to the file.
For complete information on how Googlebot and Google's other user agents treat robots.txt files, see our webmaster help center.
Rabu, 16 Agustus 2006
Back from SES San Jose
Thanks to everyone who stopped by to say hi at the Search Engine Strategies conference in San Jose last week!
I had a great time meeting people and talking about our new webmaster tools. I got to hear a lot of feedback about what webmasters liked, didn't like, and wanted to see in our Webmaster Central site. For those of you who couldn't make it or didn't find me at the conference, please feel free to post your comments and suggestions in our discussion group. I do want to hear about what you don't understand or what you want changed so I can make our webmaster tools as useful as possible.
Some of the highlights from the week:
This year, Danny Sullivan invited some of us from the team to "chat and chew" during a lunch hour panel discussion. Anyone interested in hearing about Google's webmaster tools was welcome to come and many did -- thanks for joining us! I loved showing off our product, answering questions, and getting feedback about what to work on next. Many people had already tried Sitemaps, but hadn't seen the new features like Preferred domain and full crawling errors.
One of the questions I heard more than once at the lunch was about how big a Sitemap can be, and how to use Sitemaps with very large websites. Since Google can handle all of your URLs, the goal of Sitemaps is to tell us about all of them. A Sitemap file can contain up to 50,000 URLs and should be no larger than 10MB when uncompressed. But if you have more URLs than this, simply break them up into several smaller Sitemaps and tell us about them all. You can create a Sitemap Index file, which is just a list of all your Sitemaps, to make managing several Sitemaps a little easier.
While hanging out at the Google booth I got another interesting question: One site owner told me that his site is listed in Google, but its description in the search results wasn't exactly what he wanted. (We were using the description of his site listed in the Open Directory Project.) He asked how to remove this description from Google's search results. Vanessa Fox knew the answer! To specifically prevent Google from using the Open Directory for a page's title and description, use the following meta tag:
My favorite panel of the week was definitely Pimp My Site. The whole group was dressed to match the theme as they gave some great advice to webmasters. Dax Herrera, the coolest "pimp" up there (and a fantastic piano player), mentioned that a lot of sites don't explain their product clearly on each page. For instance, when pimping Flutter Fetti, there were many instances when all the site had to do was add the word "confetti" to the product description to make it clear to search engines and to users reaching the page exactly what a Flutter Fetti stick is.
Another site pimped was a Yahoo! Stores web site. Someone from the audience asked if the webmaster could set up a Google Sitemap for their store. As Rob Snell pointed out, it's very simple: Yahoo! Stores will create a Google Sitemap for your website automatically, and even verify your ownership of the site in our webmaster tools.
Finally, if you didn't attend the Google dance, you missed out! There were Googlers dancing, eating, and having a great time with all the conference attendees. Vanessa Fox represented my team at the Meet the Google Engineers hour that we held during the dance, and I heard Matt Cutts even starred in a music video! While demo-ing Webmaster Central over in the labs area, someone asked me about the ability to share site information across multiple accounts. We associate your site verification with your Google Account, and allow multiple accounts to verify ownership of a site independently. Each account has its own verification file or meta tag, and you can remove them at any time and re-verify your site to revoke verification of a user. This means that your marketing person, your techie, and your SEO consultant can each verify the same site with their own Google Account. And if you start managing a site that someone else used to manage, all you have to do is add that site to your account and verify site ownership. You don't need to transfer the account information from the person who previously managed it.
Thanks to everyone who visited and gave us feedback. It was great to meet you!
I had a great time meeting people and talking about our new webmaster tools. I got to hear a lot of feedback about what webmasters liked, didn't like, and wanted to see in our Webmaster Central site. For those of you who couldn't make it or didn't find me at the conference, please feel free to post your comments and suggestions in our discussion group. I do want to hear about what you don't understand or what you want changed so I can make our webmaster tools as useful as possible.
Some of the highlights from the week:
This year, Danny Sullivan invited some of us from the team to "chat and chew" during a lunch hour panel discussion. Anyone interested in hearing about Google's webmaster tools was welcome to come and many did -- thanks for joining us! I loved showing off our product, answering questions, and getting feedback about what to work on next. Many people had already tried Sitemaps, but hadn't seen the new features like Preferred domain and full crawling errors.
One of the questions I heard more than once at the lunch was about how big a Sitemap can be, and how to use Sitemaps with very large websites. Since Google can handle all of your URLs, the goal of Sitemaps is to tell us about all of them. A Sitemap file can contain up to 50,000 URLs and should be no larger than 10MB when uncompressed. But if you have more URLs than this, simply break them up into several smaller Sitemaps and tell us about them all. You can create a Sitemap Index file, which is just a list of all your Sitemaps, to make managing several Sitemaps a little easier.
While hanging out at the Google booth I got another interesting question: One site owner told me that his site is listed in Google, but its description in the search results wasn't exactly what he wanted. (We were using the description of his site listed in the Open Directory Project.) He asked how to remove this description from Google's search results. Vanessa Fox knew the answer! To specifically prevent Google from using the Open Directory for a page's title and description, use the following meta tag:
<meta name="GOOGLEBOT" content="NOODP">
My favorite panel of the week was definitely Pimp My Site. The whole group was dressed to match the theme as they gave some great advice to webmasters. Dax Herrera, the coolest "pimp" up there (and a fantastic piano player), mentioned that a lot of sites don't explain their product clearly on each page. For instance, when pimping Flutter Fetti, there were many instances when all the site had to do was add the word "confetti" to the product description to make it clear to search engines and to users reaching the page exactly what a Flutter Fetti stick is.
Another site pimped was a Yahoo! Stores web site. Someone from the audience asked if the webmaster could set up a Google Sitemap for their store. As Rob Snell pointed out, it's very simple: Yahoo! Stores will create a Google Sitemap for your website automatically, and even verify your ownership of the site in our webmaster tools.
Finally, if you didn't attend the Google dance, you missed out! There were Googlers dancing, eating, and having a great time with all the conference attendees. Vanessa Fox represented my team at the Meet the Google Engineers hour that we held during the dance, and I heard Matt Cutts even starred in a music video! While demo-ing Webmaster Central over in the labs area, someone asked me about the ability to share site information across multiple accounts. We associate your site verification with your Google Account, and allow multiple accounts to verify ownership of a site independently. Each account has its own verification file or meta tag, and you can remove them at any time and re-verify your site to revoke verification of a user. This means that your marketing person, your techie, and your SEO consultant can each verify the same site with their own Google Account. And if you start managing a site that someone else used to manage, all you have to do is add that site to your account and verify site ownership. You don't need to transfer the account information from the person who previously managed it.
Thanks to everyone who visited and gave us feedback. It was great to meet you!
Senin, 07 Agustus 2006
Chat with us in person at the Search Engine Strategies conference
Got a burning question about the new Webmaster Central? Eager to give feedback about our Webmaster tools?
Of course, we always appreciate hearing from you in our recently expanded Webmaster Help discussion group. But if you're one of thousands of Webmasters attending the Search Engine Strategies conference ("SES") this week in San Jose, California, we'd particularly enjoy meeting you in person!
Amanda, Vanessa, Matt, and I (along with many other Googlers) will be speaking at various sessions throughout the conference, as well as hanging out in the exhibit hall. On Tuesday and Wednesday, Amanda will also be spending some quality time in the Google booth. On Tuesday night at the Googleplex, a huge mass of Googlers (including all of us) will be demo'ing products and services, answering questions, and enjoying the food, libations, and live music with a broad array of guests from SES at the annual Google Dance.
Interested in learning more details? Check out the post on the main Google blog.
Of course, we always appreciate hearing from you in our recently expanded Webmaster Help discussion group. But if you're one of thousands of Webmasters attending the Search Engine Strategies conference ("SES") this week in San Jose, California, we'd particularly enjoy meeting you in person!
Amanda, Vanessa, Matt, and I (along with many other Googlers) will be speaking at various sessions throughout the conference, as well as hanging out in the exhibit hall. On Tuesday and Wednesday, Amanda will also be spending some quality time in the Google booth. On Tuesday night at the Googleplex, a huge mass of Googlers (including all of us) will be demo'ing products and services, answering questions, and enjoying the food, libations, and live music with a broad array of guests from SES at the annual Google Dance.
Interested in learning more details? Check out the post on the main Google blog.
Jumat, 04 Agustus 2006
More webmaster tools
With our latest release, we've done more than just change our name --we've listened to you and added some features and enhanced others as a result.
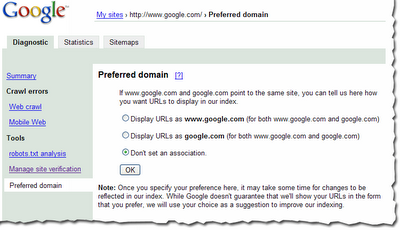
Telling us your preferred domain URL format
Some webmasters want their sites indexed under the www version of their domain; others want their sites indexed without the www. Which do you prefer? Now you can tell us and we'll do our best to do what you like when crawling and indexing your site. Note that it might take some time for changes to be reflected in our index, but if you notice that your site is currently indexed using both versions of your domain, tell us your preference.
 Downloading query stats for all subfolders
Downloading query stats for all subfolders
Do you like seeing the top queries that returned your site? Now you can download a CSV file that shows you the top queries for each of your subfolders in the results.
Seeing revamped crawl errors
Now you can see at a glance the types of errors we get when crawling your site. You can see a table of the errors on the summary page, with counts for each error type. On the crawl errors page, you can still see the number of errors for type, as well as filter errors by date.
 Managing verification
Managing verification
If somebody from your team no longer has write access to a site and should no longer be a verified owner of it, you can remove the verification file or meta tag for that person. When we periodically check verification, that person's account will no longer be verified for the site. We've added the ability to let you request that check so that you don't have to wait for our periodic process. Simply click the "Manage site verification" link, make note of the verification files and meta tags that may exist for the site, remove any that are no longer valid, and click the "Reverify all site owners" button. We'll check all accounts that are verified for the site and only leave verification in place for accounts for which we find a verification file or meta tag.
Other enhancements
You'll find a number of other smaller enhancements throughout the webmaster tools, all based on your feedback. Thanks as always for your input -- please let us know what you think in our newly revamped Google Group.
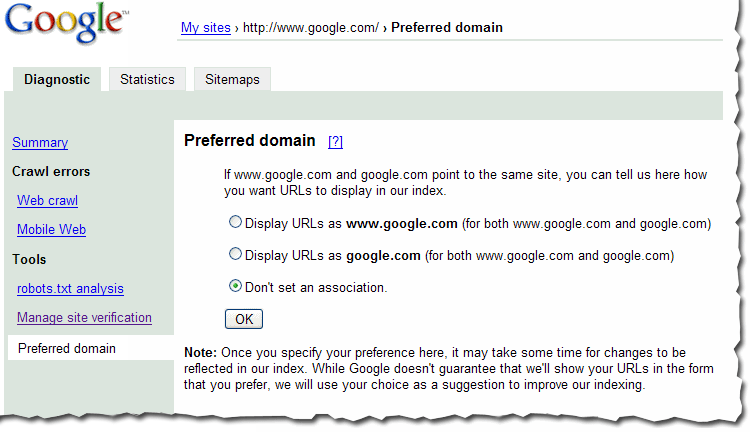
Telling us your preferred domain URL format
Some webmasters want their sites indexed under the www version of their domain; others want their sites indexed without the www. Which do you prefer? Now you can tell us and we'll do our best to do what you like when crawling and indexing your site. Note that it might take some time for changes to be reflected in our index, but if you notice that your site is currently indexed using both versions of your domain, tell us your preference.
 Downloading query stats for all subfolders
Downloading query stats for all subfoldersDo you like seeing the top queries that returned your site? Now you can download a CSV file that shows you the top queries for each of your subfolders in the results.
Seeing revamped crawl errors
Now you can see at a glance the types of errors we get when crawling your site. You can see a table of the errors on the summary page, with counts for each error type. On the crawl errors page, you can still see the number of errors for type, as well as filter errors by date.
 Managing verification
Managing verification If somebody from your team no longer has write access to a site and should no longer be a verified owner of it, you can remove the verification file or meta tag for that person. When we periodically check verification, that person's account will no longer be verified for the site. We've added the ability to let you request that check so that you don't have to wait for our periodic process. Simply click the "Manage site verification" link, make note of the verification files and meta tags that may exist for the site, remove any that are no longer valid, and click the "Reverify all site owners" button. We'll check all accounts that are verified for the site and only leave verification in place for accounts for which we find a verification file or meta tag.
Other enhancements
You'll find a number of other smaller enhancements throughout the webmaster tools, all based on your feedback. Thanks as always for your input -- please let us know what you think in our newly revamped Google Group.
Langganan:
Postingan (Atom)